Adversarial Video Generation
Adversarial Video Generation
This project was forked from dyelax’s work and immigrated to TensorFlow1.2 and Python3, in order to be compatible to GTX1080 or later version GPU.
Adversarial generation uses two networks – a generator and a discriminator – to improve the sharpness of generated images. Given the past four frames of video, the generator learns to generate accurate predictions for the next frame. Given either a generated or a real-world image, the discriminator learns to correctly classify between generated and real. The two networks “compete,” with the generator attempting to fool the discriminator into classifying its output as real. This forces the generator to create frames that are very similar to what real frames in the domain might look like.
Results
We collected the data from a basketball game and a video game Snake.
After the first 10000 times training, the last frame of the Snake Game looked still fuzzy.
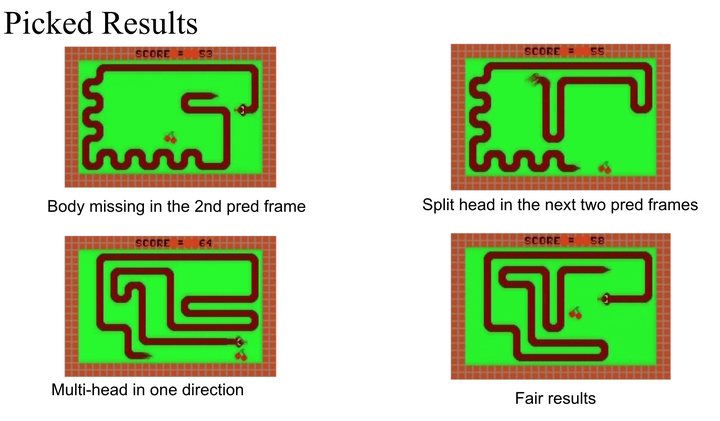
The detailed results is shown at here.
After another 40000 times training, the basketball sence looked like still fuzzy, while the Snake sence looked better.
An interesting finding was that when the snake met the cherry, which was used to earn points, it felt “puzzled” about which direction to take. This “puzzled” also exists when the snake went close to the wall or its own body.